Appearance
附录 A Concurrency II 并发编程 II
by Brett L. Schuchert
This appendix supports and amplifies the Concurrency chapter on page 177. It is written as a series of independent topics and you can generally read them in any order. There is some duplication between sections to allow for such reading.
本附录是对第 177 页并发编程章节的补充和扩展。本附录以一系列独立主题的形式撰写,通常可以按任意顺序阅读。各节之间存在一些内容重复,以保证独立阅读的完整性。
CLIENT/SERVER EXAMPLE 客户端/服务器示例
Imagine a simple client/server application. A server sits and waits listening on a socket for a client to connect. A client connects and sends a request.
想象一个简单的客户端/服务器应用程序。服务器在 socket 上监听,等待客户端连接。客户端连接后发送一个请求。
The Server 服务器端
Here is a simplified version of a server application. Full source for this example is available starting on page 343, Client/Server Nonthreaded.
下面是一个简化版的服务器应用程序。该示例的完整源代码从第 343 页("非线程化的客户端/服务器")开始。
java
ServerSocket serverSocket = new ServerSocket(8009);
while (keepProcessing) {
try {
Socket socket = serverSocket.accept();
process(socket);
} catch (Exception e) {
handle(e);
}
}This simple application waits for a connection, processes an incoming message, and then again waits for the next client request to come in. Here's client code that connects to this server:
这个简单的应用程序等待连接,处理传入的消息,然后再次等待下一个客户端请求到来。下面是连接到该服务器的客户端代码:
java
private void connectSendReceive(int i) {
try {
Socket socket = new Socket("localhost", PORT);
MessageUtils.sendMessage(socket, Integer.toString(i));
MessageUtils.getMessage(socket);
socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}How well does this client/server pair perform? How can we formally describe that performance? Here's a test that asserts that the performance is "acceptable":
这个客户端/服务器组合的性能如何?我们如何正式描述其性能?下面是断言性能"可接受"的测试:
java
@Test(timeout = 10000)
public void shouldRunInUnder10Seconds() throws Exception {
Thread[] threads = createThreads();
startAllThreadsw(threads);
waitForAllThreadsToFinish(threads);
}The setup is left out to keep the example simple (see "ClientTest.java" on page 344). This test asserts that it should complete within 10,000 milliseconds.
为了简化示例,省略了设置部分(参见第 344 页的"ClientTest.java")。该测试断言应在 10,000 毫秒内完成。
This is a classic example of validating the throughput of a system. This system should complete a series of client requests in ten seconds. So long as the server can process each individual client request in time, the test will pass.
这是验证系统吞吐量的经典示例。该系统应在十秒内完成一系列客户端请求。只要服务器能够及时处理每个客户端请求,测试就会通过。
What happens if the test fails? Short of developing some kind of event polling loop, there is not much to do within a single thread that will make this code any faster. Will using multiple threads solve the problem? It might, but we need to know where the time is being spent. There are two possibilities:
如果测试失败怎么办?除非开发某种事件轮询循环,否则在单线程内没有太多办法能让这段代码更快。使用多线程能解决问题吗?也许可以,但我们需要知道时间花在哪里。有两种可能性:
- I/O--using a socket, connecting to a database, waiting for virtual memory swapping, and so on.
- Processor--numerical calculations, regular expression processing, garbage collection, and so on.
- I/O——使用 socket、连接数据库、等待虚拟内存交换等。
- Processor——数值计算、正则表达式处理、垃圾回收等。
Systems typically have some of each, but for a given operation one tends to dominate. If the code is processor bound, more processing hardware can improve throughput, making our test pass. But there are only so many CPU cycles available, so adding threads to a processor-bound problem will not make it go faster.
系统通常同时包含这两类操作,但对于给定的操作,往往其中一类占主导。如果代码是 processor bound(处理器密集型)的,更多的处理硬件可以提高吞吐量,使测试通过。但 CPU 周期有限,所以为处理器密集型问题添加线程不会让它更快。
On the other hand, if the process is I/O bound, then concurrency can increase efficiency. When one part of the system is waiting for I/O, another part can use that wait time to process something else, making more effective use of the available CPU.
另一方面,如果进程是 I/O bound(I/O 密集型)的,并发可以提高效率。当系统的一部分在等待 I/O 时,另一部分可以利用这段等待时间来处理其他事情,从而更有效地利用可用的 CPU。
Adding Threading 添加线程
Assume for the moment that the performance test fails. How can we improve the throughput so that the performance test passes? If the process method of the server is I/O bound, then here is one way to make the server use threads (just change the processMessage):
假设性能测试失败了。我们如何提高吞吐量以使性能测试通过?如果服务器的 process 方法是 I/O 密集型的,那么下面是让服务器使用线程的一种方式(只需修改 processMessage):
java
void process(final Socket socket) {
if (socket == null)
return;
Runnable clientHandler = new Runnable() {
public void run() {
try {
String message = MessageUtils.getMessage(socket);
MessageUtils.sendMessage(socket, "Processed: " + message);
closeIgnoringException(socket);
} catch (Exception e) {
e.printStackTrace();
}
}
};
Thread clientConnection = new Thread(clientHandler);
clientConnection.start();
}Assume that this change causes the test to pass;1 the code is complete, correct?
假设这个修改使测试通过了^[1];代码就完成了,对吗?
- You can verify that for yourself by trying out the before and after code. Review the nonthreaded code starting on page 343. Review the threaded code starting on page 346.
[1] 你可以自己尝试修改前后的代码来验证。从第 343 页开始查阅非线程化代码,从第 346 页开始查阅线程化代码。
Server Observations 服务器端观察
The updated server completes the test successfully in just over one second. Unfortunately, this solution is a bit naive and introduces some new problems.
更新后的服务器仅用一秒多就成功完成了测试。不幸的是,这个方案有些天真,引入了一些新问题。
How many threads might our server create? The code sets no limit, so the we could feasibly hit the limit imposed by the Java Virtual Machine (JVM). For many simple systems this may suffice. But what if the system is meant to support many users on the public net? If too many users connect at the same time, the system might grind to a halt.
服务器可能会创建多少线程?代码没有设置限制,所以我们很可能达到 Java Virtual Machine (JVM) 所施加的上限。对于许多简单的系统,这可能足够了。但如果系统旨在支持公共网络上的大量用户呢?如果太多用户同时连接,系统可能会停滞不前。
But set the behavioral problem aside for the moment. The solution shown has problems of cleanliness and structure. How many responsibilities does the server code have?
但暂时先搁置行为问题。所示的解决方案在整洁性和结构方面存在问题。服务器代码有多少职责?
- Socket connection management
- Client processing
- Threading policy
- Server shutdown policy
- Socket 连接管理
- 客户端处理
- 线程策略
- 服务器关闭策略
Unfortunately, all these responsibilities live in the process function. In addition, the code crosses many different levels of abstraction. So, small as the process function is, it needs to be repartitioned.
不幸的是,所有这些职责都在 process 函数中。此外,代码跨越了许多不同的抽象层次。因此,尽管 process 函数很小,但仍需要重新划分。
The server has several reasons to change; therefore it violates the Single Responsibility Principle. To keep concurrent systems clean, thread management should be kept to a few, well-controlled places. What's more, any code that manages threads should do nothing other than thread management. Why? If for no other reason than that tracking down concurrency issues is hard enough without having to unwind other nonconcurrency issues at the same time.
服务器有多个修改原因;因此它违反了单一职责原则(Single Responsibility Principle)。为了保持并发系统的整洁,线程管理应集中在少数几个受控的地方。而且,任何管理线程的代码都只应做线程管理工作。为什么?即使没有其他原因,也因为追踪并发问题本身就够难了,更不必说同时还要拆解其他非并发问题。
If we create a separate class for each of the responsibilities listed above, including the thread management responsibility, then when we change the thread management strategy, the change will impact less overall code and will not pollute the other responsibilities. This also makes it much easier to test all the other responsibilities without having to worry about threading. Here is an updated version that does just that:
如果我们为上面列出的每一项职责创建单独的类,包括线程管理职责,那么当我们更改线程管理策略时,变更将影响更少的代码,也不会污染其他职责。这也使得在不担心线程问题的情况下测试所有其他职责变得更加容易。下面是做到这一点的更新版本:
java
public void run() {
while (keepProcessing) {
try {
ClientConnection clientConnection = connectionManager.awaitClient();
ClientRequestProcessor requestProcessor
= new ClientRequestProcessor(clientConnection);
clientScheduler.schedule(requestProcessor);
} catch (Exception e) {
e.printStackTrace();
}
}
connectionManager.shutdown();
}This now focuses all things thread-related into one place, clientScheduler. If there are concurrency problems, there is just one place to look:
这样就把所有与线程相关的内容集中在了一个地方——clientScheduler。如果存在并发问题,只需查看一个地方:
java
public interface ClientScheduler {
void schedule(ClientRequestProcessor requestProcessor);
}The current policy is easy to implement:
当前的策略很容易实现:
java
public class ThreadPerRequestScheduler implements ClientScheduler {
public void schedule(final ClientRequestProcessor requestProcessor) {
Runnable runnable = new Runnable() {
public void run() {
requestProcessor.process();
}
};
Thread thread = new Thread(runnable);
thread.start();
}
}Having isolated all the thread management into a single place, it is much easier to change the way we control threads. For example, moving to the Java 5 Executor framework involves writing a new class and plugging it in (Listing A-1).
将所有线程管理隔离到一个地方后,更改线程控制方式变得更加容易。例如,迁移到 Java 5 的 Executor 框架只需要编写一个新类并插入即可(代码清单 A-1)。
代码清单 A-1 ExecutorClientScheduler.java
java
import java.util.concurrent.Executor;
import java.util.concurrent.Executors;
public class ExecutorClientScheduler implements ClientScheduler {
Executor executor;
public ExecutorClientScheduler(int availableThreads) {
executor = Executors.newFixedThreadPool(availableThreads);
}
public void schedule(final ClientRequestProcessor requestProcessor) {
Runnable runnable = new Runnable() {
public void run() {
requestProcessor.process();
}
};
executor.execute(runnable);
}
}Conclusion 结论
Introducing concurrency in this particular example demonstrates a way to improve the throughput of a system and one way of validating that throughput through a testing framework. Focusing all concurrency code into a small number of classes is an example of applying the Single Responsibility Principle. In the case of concurrent programming, this becomes especially important because of its complexity.
在这个特定示例中引入并发,展示了一种提高系统吞吐量的方法以及通过测试框架验证吞吐量的一种方式。将所有并发代码集中在少数几个类中是应用单一职责原则的一个示例。在并发编程中,这一点尤为重要,因为并发编程本身就是复杂的。
POSSIBLE PATHS OF EXECUTION 可能的执行路径
Review the method incrementValue, a one-line Java method with no looping or branching:
回顾一下 incrementValue 方法,这是一个没有循环和分支的单行 Java 方法:
java
public class IdGenerator {
int lastIdUsed;
public int incrementValue() {
return ++lastIdUsed;
}
}Ignore integer overflow and assume that only one thread has access to a single instance of IdGenerator. In this case there is a single path of execution and a single guaranteed result:
忽略整数溢出,假设只有一个线程能访问 IdGenerator 的单个实例。在这种情况下,只有一条执行路径和一个确定的结果:
- The value returned is equal to the value of lastIdUsed, both of which are one greater than just before calling the method.
- 返回的值等于 lastIdUsed 的值,两者都比调用方法之前大一。
What happens if we use two threads and leave the method unchanged? What are the possible outcomes if each thread calls incrementValue once? How many possible paths of execution are there? First, the outcomes (assume lastIdUsed starts with a value of 93):
如果我们使用两个线程而方法不变,会发生什么?如果每个线程各调用一次 incrementValue,可能的结果有哪些?有多少条可能的执行路径?首先,结果(假设 lastIdUsed 初始值为 93):
- Thread 1 gets the value of 94, thread 2 gets the value of 95, and lastIdUsed is now 95.
- Thread 1 gets the value of 95, thread 2 gets the value of 94, and lastIdUsed is now 95.
- Thread 1 gets the value of 94, thread 2 gets the value of 94, and lastIdUsed is now 94.
- 线程 1 得到值 94,线程 2 得到值 95,lastIdUsed 现在是 95。
- 线程 1 得到值 95,线程 2 得到值 94,lastIdUsed 现在是 95。
- 线程 1 得到值 94,线程 2 得到值 94,lastIdUsed 现在是 94。
The final result, while surprising, is possible. To see how these different results are possible, we need to understand the number of possible paths of execution and how the Java Virtual Machine executes them.
最后一个结果虽然令人惊讶,但确实可能发生。要理解这些不同结果为何可能,我们需要了解可能的执行路径数量以及 Java Virtual Machine 如何执行它们。
Number of Paths 路径数量
To calculate the number of possible execution paths, we'll start with the generated byte-code. The one line of java (return ++lastIdUsed;) becomes eight byte-code instructions. It is possible for the two threads to interleave the execution of these eight instructions the way a card dealer interleaves cards as he shuffles a deck.2 Even with only eight cards in each hand, there are a remarkable number of shuffled outcomes.
为了计算可能的执行路径数量,我们将从生成的字节码开始。一行 Java 代码(return ++lastIdUsed;)变成了八条字节码指令。两个线程可以像发牌员洗牌时那样交错执行这八条指令^[2]。即使每手只有八张牌,洗牌的结果数量也是惊人的。
- This is a bit of a simplification. However, for the purpose of this discussion, we can use this simplifying model.
[2] 这里有所简化。不过,就本讨论的目的而言,我们可以使用这个简化模型。
For this simple case of N instructions in a sequence, no looping or conditionals, and T threads, the total number of possible execution paths is equal to
对于这个简单的场景——N 条指令的序列,没有循环和条件分支,T 个线程——可能的执行路径总数等于
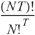
Calculating the Possible Orderings 计算可能的排列
This comes from an email from Uncle Bob to Brett:
以下内容来自 Uncle Bob 给 Brett 的一封邮件:
With N steps and T threads there are T* N total steps. Prior to each step there is a context switch that chooses between the T threads. Each path can thus be represented as a string of digits denoting the context switches. Given steps A and B and threads 1 and 2, the six possible paths are 1122, 1212, 1221, 2112, 2121, and 2211. Or, in terms of steps it is A1B1A2B2, A1A2B1B2, A1A2B2B1, A2A1B1B2, A2A1B2B1, and A2B2A1B1. For three threads the sequence is 112233, 112323, 113223, 113232, 112233, 121233, 121323, 121332, 123132, 123123, ....
对于 N 步和 T 个线程,共有 T*N 个总步骤。每一步之前都有一个上下文切换,从 T 个线程中选择一个。因此每条路径都可以表示为一个数字串,表示上下文切换。给定步骤 A 和 B 以及线程 1 和 2,六条可能的路径是 1122、1212、1221、2112、2121 和 2211。或者用步骤表示为 A1B1A2B2、A1A2B1B2、A1A2B2B1、A2A1B1B2、A2A1B2B1 和 A2B2A1B1。对于三个线程,序列为 112233、112323、113223、113232、112233、121233、121323、121332、123132、123123、...。
One characteristic of these strings is that there must always be N instances of each T. So the string 111111 is invalid because it has six instances of 1 and zero instances of 2 and 3.
这些字符串的一个特征是每个 T 必须始终有 N 个实例。所以字符串 111111 是无效的,因为它有六个 1 的实例,而 2 和 3 的实例为零。
So we want the permutations of N 1's, N 2's, ... and N T's. This is really just the permutations of N* T things taken N* T at a time, which is (N* T)!, but with all the duplicates removed. So the trick is to count the duplicates and subtract that from (N* T)!.
所以我们需要的是 N 个 1、N 个 2、...和 N 个 T 的排列。这实际上就是 NT 个事物取 NT 个的排列,即 (NT)!,但要去除所有重复项。所以技巧在于计算重复项并从 (NT)! 中减去。
Given two steps and two threads, how many duplicates are there? Each four-digit string has two 1s and two 2s. Each of those pairs could be swapped without changing the sense of the string. You could swap the 1s or the 2s both, or neither. So there are four isomorphs for each string, which means that there are three duplicates. So three out of four of the options are duplicates; alternatively one of four of the permutations are NOT duplicates. 4! * .25 = 6. So this reasoning seems to work.
给定两步和两个线程,有多少重复项?每个四位数字符串有两个 1 和两个 2。每对数字可以在不改变字符串含义的情况下交换。你可以交换 1 或 2,或两者都交换,或都不交换。所以每个字符串有四个同构体,这意味着有三个重复项。因此四分之三的选项是重复的;换言之,四分之一的排列不是重复的。4! * 0.25 = 6。所以这个推理似乎是正确的。
How many duplicates are there? In the case where N = 2 and T = 2, I could swap the 1s, the 2s, or both. In the case where N = 2 and T = 3, I could swap the 1s, the 2s, the 3s, 1s and 2s, 1s and 3s, or 2s and 3s. Swapping is just the permutations of N. Let's say there are P permutations of N. The number of different ways to arrange those permutations are P**T.
有多少重复项?在 N = 2 且 T = 2 的情况下,我可以交换 1、2 或两者都交换。在 N = 2 且 T = 3 的情况下,我可以交换 1、2、3、1 和 2、1 和 3、或 2 和 3。交换就是 N 的排列。假设 N 有 P 种排列,那么排列这些排列的不同方式有 P^T 种。
So the number of possible isomorphs is N!**T. And so the number of paths is (T*N)!/(N!**T). Again, in our T = 2, N = 2 case we get 6 (24/4).
所以可能的同构体数量是 (N!)^T。因此路径数量为 (T*N)!/(N!)^T。同样,在 T = 2、N = 2 的情况下,我们得到 6(24/4)。
For N = 2 and T = 3 we get 720/8 = 90.
对于 N = 2 且 T = 3,我们得到 720/8 = 90。
For N = 3 and T = 3 we get 9!/6^3 = 1680.
对于 N = 3 且 T = 3,我们得到 9!/6^3 = 1680。
For our simple case of one line of Java code, which equates to eight lines of byte-code and two threads, the total number of possible paths of execution is 12,870. If the type of lastIdUsed is a long, then every read/write becomes two operations instead of one, and the number of possible orderings becomes 2,704,156.
对于我们的简单情况——一行 Java 代码,相当于八行字节码和两个线程——可能的执行路径总数为 12,870。如果 lastIdUsed 的类型是 long,那么每次读/写变成两次操作而非一次,可能的排列数量变为 2,704,156。
What happens if we make one change to this method?
如果我们对这个方法做一个修改会怎样?
java
public synchronized void incrementValue() {
++lastIdUsed;
}The number of possible execution pathways becomes two for two threads and N! in the general case.
对于两个线程,可能的执行路径数变为两条,一般情况下为 N!。
Digging Deeper 深入探究
What about the surprising result that two threads could both call the method once (before we added synchronized) and get the same numeric result? How is that possible? First things first.
那两个线程都能调用一次方法(在我们添加 synchronized 之前)并得到相同的数值结果,这个令人惊讶的结果是怎么回事?这怎么可能?让我们先从基础说起。
What is an atomic operation? We can define an atomic operation as any operation that is uninterruptable. For example, in the following code, line 5, where 0 is assigned to lastid, is atomic because according to the Java Memory model, assignment to a 32-bit value is uninterruptable.
什么是原子操作(atomic operation)?我们可以将原子操作定义为任何不可中断的操作。例如,在下面的代码中,第 5 行将 0 赋值给 lastId 是原子的,因为根据 Java 内存模型,对 32 位值的赋值是不可中断的。
java
01: public class Example {
02: int lastId;
03:
04: public void resetId() {
05: value = 0;
06: }
07:
08: public int getNextId() {
09: ++value;
10: }
11:}What happens if we change type of lastId from int to long? Is line 5 still atomic? Not according to the JVM specification. It could be atomic on a particular processor, but according to the JVM specification, assignment to any 64-bit value requires two 32-bit assignments. This means that between the first 32-bit assignment and the second 32-bit assignment, some other thread could sneak in and change one of the values.
如果我们把 lastId 的类型从 int 改为 long 会怎样?第 5 行还是原子的吗?按照 JVM 规范来说不是。在某个特定处理器上它可能是原子的,但根据 JVM 规范,对任何 64 位值的赋值都需要两次 32 位赋值。这意味着在第一次 32 位赋值和第二次 32 位赋值之间,其他线程可能趁虚而入改变其中一个值。
What about the pre-increment operator, ++, on line 9? The pre-increment operator can be interrupted, so it is not atomic. To understand, let's review the byte-code of both of these methods in detail.
那么第 9 行的前置自增运算符 ++ 呢?前置自增运算符可以被中断,所以它不是原子的。要理解这一点,让我们详细回顾这两个方法的字节码。
Before we go any further, here are three definitions that will be important:
在继续之前,这里给出三个重要的定义:
- Frame--Every method invocation requires a frame. The frame includes the return address, any parameters passed into the method and the local variables defined in the method. This is a standard technique used to define a call stack, which is used by modern languages to allow for basic function/method invocation and to allow for recursive invocation.
- Frame(栈帧)——每次方法调用都需要一个栈帧。栈帧包括返回地址、传入方法的任何参数以及方法中定义的局部变量。这是定义调用栈的标准技术,现代语言使用调用栈来实现基本的函数/方法调用和递归调用。
- Local variable--Any variables defined in the scope of the method. All nonstatic methods have at least one variable, this, which represents the current object, the object that received the most recent message (in the current thread), which caused the method invocation.
- Local variable(局部变量)——在方法作用域内定义的任何变量。所有非静态方法至少有一个变量 this,它代表当前对象,即接收到最新消息(在当前线程中)并导致方法调用的对象。
- Operand stack--Many of the instructions in the Java Virtual Machine take parameters. The operand stack is where those parameters are put. The stack is a standard last-in, first-out (LIFO) data structure.
- Operand stack(操作数栈)——Java Virtual Machine 中的许多指令需要参数。操作数栈就是放置这些参数的地方。该栈是一个标准的后进先出(LIFO)数据结构。
Here is the byte-code generated for resetId():
下面是 resetId() 生成的字节码:


These three instructions are guaranteed to be atomic because, although the thread executing them could be interrupted after any one of them, the information for the PUTFIELD instruction (the constant value 0 on the top of the stack and the reference to this one below the top, along with the field value) cannot be touched by another thread. So when the assignment occurs, we are guaranteed that the value 0 will be stored in the field value. The operation is atomic. The operands all deal with information local to the method, so there is no interference between multiple threads.
这三条指令保证是原子的,因为虽然执行它们的线程可能在任何一条之后被中断,但 PUTFIELD 指令的信息(栈顶的常量值 0 和栈顶下方一个位置的 this 引用,以及字段值)不能被其他线程触及。所以当赋值发生时,我们保证值 0 会被存储到字段 value 中。操作是原子的。操作数都处理方法的局部信息,因此不存在多线程之间的干扰。
So if these three instructions are executed by ten threads, there are 4.38679733629e+24 possible orderings. However, there is only one possible outcome, so the different orderings are irrelevant. It just so happens that the same outcome is guaranteed for longs in this case as well. Why? All ten threads are assigning a constant value. Even if they interleave with each other, the end result is the same.
因此,如果这三条指令由十个线程执行,有 4.38679733629e+24 种可能的排列。然而,只有一种可能的结果,所以不同的排列是无关紧要的。恰好在这种情况下,对于 long 类型也能保证相同的结果。为什么?所有十个线程都在赋一个常量值。即使它们相互交错,最终结果也是相同的。
With the ++ operation in the getNextId method, there are going to be problems. Assume that lastId holds 42 at the beginning of this method. Here is the byte-code for this new method:
但 getNextId 方法中的 ++ 操作就会有问题。假设 lastId 在方法开始时的值为 42。下面是这个新方法的字节码:
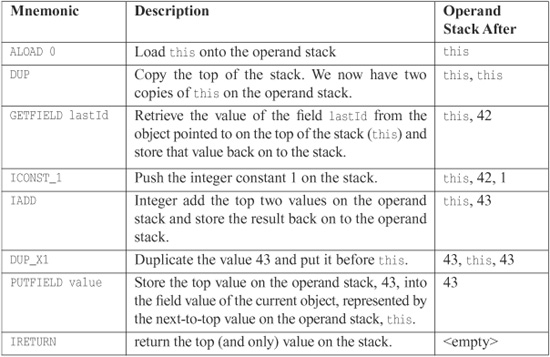
Imagine the case where the first thread completes the first three instructions, up to and including GETFIELD, and then it is interrupted. A second thread takes over and performs the entire method, incrementing lastId by one; it gets 43 back. Then the first thread picks up where it left off; 42 is still on the operand stack because that was the value of lastId when it executed GETFIELD. It adds one to get 43 again and stores the result. The value 43 is returned to the first thread as well. The result is that one of the increments is lost because the first thread stepped on the second thread after the second thread interrupted the first thread.
想象一下这种情况:第一个线程完成了前三条指令,包括 GETFIELD,然后被中断。第二个线程接管并执行整个方法,将 lastId 递增一;它得到 43。然后第一个线程从中断处继续;42 仍在操作数栈上,因为那是它执行 GETFIELD 时 lastId 的值。它加一再次得到 43 并存储结果。值 43 也返回给了第一个线程。结果是一次递增丢失了,因为第二个线程中断了第一个线程之后,第一个线程又踩了第二个线程的结果。
Making the getNexId() method synchronized fixes this problem.
将 getNextId() 方法设为 synchronized 可以解决这个问题。
Conclusion 结论
An intimate understanding of byte-code is not necessary to understand how threads can step on each other. If you can understand this one example, it should demonstrate the possibility of multiple threads stepping on each other, which is enough knowledge.
理解线程如何相互踩踏,并不需要深入了解字节码。如果你能理解这一个示例,它应该能展示多线程相互踩踏的可能性,这就足够了。
That being said, what this trivial example demonstrates is a need to understand the memory model enough to know what is and is not safe. It is a common misconception that the ++ (pre- or post-increment) operator is atomic, and it clearly is not. This means you need to know:
话虽如此,这个简单示例所展示的是需要理解内存模型,以了解什么是安全的、什么不是。一个常见的误解是 ++(前置或后置自增)运算符是原子的,但显然不是。这意味着你需要知道:
- Where there are shared objects/values
- The code that can cause concurrent read/update issues
- How to guard such concurrent issues from happening
- 哪里有共享对象/值
- 哪些代码可能导致并发读/更新问题
- 如何防止此类并发问题的发生
KNOWING YOUR LIBRARY 了解你的类库
Executor Framework Executor 框架
As demonstrated in the ExecutorClientScheduler.java on page 321, the Executor framework introduced in Java 5 allows for sophisticated execution using thread pools. This is a class in the java.util.concurrent package.
如第 321 页的 ExecutorClientScheduler.java 所示,Java 5 引入的 Executor 框架允许使用线程池进行复杂的执行。它是 java.util.concurrent 包中的一个类。
If you are creating threads and are not using a thread pool or are using a hand-written one, you should consider using the Executor. It will make your code cleaner, easier to follow, and smaller.
如果你正在创建线程而不使用线程池,或者使用手写的线程池,你应该考虑使用 Executor。它将使你的代码更整洁、更易于理解和更精简。
The Executor framework will pool threads, resize automatically, and recreate threads if necessary. It also supports futures, a common concurrent programming construct. The Executor framework works with classes that implement Runnable and also works with classes that implement the Callable interface. A Callable looks like a Runnable, but it can return a result, which is a common need in multithreaded solutions.
Executor 框架会池化线程、自动调整大小,并在必要时重新创建线程。它还支持 future,一种常见的并发编程构造。Executor 框架既可以与实现 Runnable 接口的类一起工作,也可以与实现 Callable 接口的类一起工作。Callable 看起来像 Runnable,但它可以返回结果,这在多线程解决方案中是常见需求。
A future is handy when code needs to execute multiple, independent operations and wait for both to finish:
当代码需要执行多个独立操作并等待它们都完成时,future 非常方便:
java
public String processRequest(String message) throws Exception {
Callable<String> makeExternalCall = new Callable<String>() {
public String call() throws Exception {
String result = "";
// make external request
return result;
}
};
Future<String> result = executorService.submit(makeExternalCall);
String partialResult = doSomeLocalProcessing();
return result.get() + partialResult;
}In this example, the method starts executing the makeExternalCall object. The method continues other processing. The final line calls result.get(), which blocks until the future completes.
在这个示例中,方法开始执行 makeExternalCall 对象。方法继续其他处理。最后一行调用 result.get(),它会阻塞直到 future 完成。
Nonblocking Solutions 非阻塞方案
The Java 5 VM takes advantage of modern processor design, which supports reliable, nonblocking updates. Consider, for example, a class that uses synchronization (and therefore blocking) to provide a thread-safe update of a value:
Java 5 虚拟机利用了现代处理器设计的优势,支持可靠的非阻塞更新。例如,考虑一个使用同步(因此是阻塞)来提供线程安全的值更新的类:
java
public class ObjectWithValue {
private int value;
public void synchronized incrementValue() { ++value; }
public int getValue() { return value; }
}Java 5 has a series of new classes for situations like this: AtomicBoolean, AtomicInteger, and AtomicReference are three examples; there are several more. We can rewrite the above code to use a nonblocking approach as follows:
Java 5 有一系列新的类来处理这种情况:AtomicBoolean、AtomicInteger 和 AtomicReference 是三个例子;还有更多。我们可以用非阻塞方式重写上面的代码,如下所示:
java
public class ObjectWithValue {
private AtomicInteger value = new AtomicInteger(0);
public void incrementValue() {
value.incrementAndGet();
}
public int getValue() {
return value.get();
}
}Even though this uses an object instead of a primitive and sends messages like incrementAndGet() instead of ++, the performance of this class will nearly always beat the previous version. In some cases it will only be slightly faster, but the cases where it will be slower are virtually nonexistent.
尽管这里使用了一个对象而非基本类型,并且发送像 incrementAndGet() 这样的消息而非 ++,这个类的性能几乎总是优于前一个版本。在某些情况下只会快一点,但它变慢的情况几乎不存在。
How is this possible? Modern processors have an operation typically called Compare and Swap (CAS). This operation is analogous to optimistic locking in databases, whereas the synchronized version is analogous to pessimistic locking.
这怎么可能?现代处理器有一种通常称为 Compare and Swap (CAS)(比较并交换)的操作。这个操作类似于数据库中的乐观锁,而 synchronized 版本类似于悲观锁。
The synchronized keyword always acquires a lock, even when a second thread is not trying to update the same value. Even though the performance of intrinsic locks has improved from version to version, they are still costly.
synchronized 关键字总是获取锁,即使没有第二个线程试图更新同一个值。尽管内置锁的性能在各个版本中有所提升,但开销仍然不小。
The nonblocking version starts with the assumption that multiple threads generally do not modify the same value often enough that a problem will arise. Instead, it efficiently detects whether such a situation has occurred and retries until the update happens successfully. This detection is almost always less costly than acquiring a lock, even in moderate to high contention situations.
非阻塞版本假设多个线程通常不会频繁修改同一个值以至于产生问题。相反,它高效地检测这种情况是否发生,并重试直到更新成功。这种检测几乎总是比获取锁的开销更小,即使在中等到高竞争的情况下也是如此。
How does the Virtual Machine accomplish this? The CAS operation is atomic. Logically, the CAS operation looks something like the following:
虚拟机是如何实现这一点的?CAS 操作是原子的。从逻辑上看,CAS 操作大致如下:
java
int variableBeingSet;
void simulateNonBlockingSet(int newValue) {
int currentValue;
do {
currentValue = variableBeingSet
} while(currentValue != compareAndSwap(currentValue, newValue));
}
int synchronized compareAndSwap(int currentValue, int newValue) {
if(variableBeingSet == currentValue) {
variableBeingSet = newValue;
return currentValue;
}
return variableBeingSet;
}When a method attempts to update a shared variable, the CAS operation verifies that the variable getting set still has the last known value. If so, then the variable is changed. If not, then the variable is not set because another thread managed to get in the way. The method making the attempt (using the CAS operation) sees that the change was not made and retries.
当一个方法试图更新共享变量时,CAS 操作验证该变量是否仍保持最后已知的值。如果是,则更改该变量。如果不是,则不设置该变量,因为另一个线程设法介入了。尝试修改的方法(使用 CAS 操作)发现更改未成功,然后重试。
Nonthread-Safe Classes 非线程安全的类
There are some classes that are inherently not thread safe. Here are a few examples:
有些类天生就不是线程安全的。以下是几个例子:
- SimpleDateFormat
- Database Connections
- Containers in java.util
- Servlets
- SimpleDateFormat
- 数据库连接
- java.util 中的容器
- Servlets
Note that some collection classes have individual methods that are thread-safe. However, any operation that involves calling more than one method is not. For example, if you do not want to replace something in a HashTable because it is already there, you might write the following code:
请注意,某些集合类的单个方法是线程安全的。然而,任何涉及调用多个方法的操作都不是线程安全的。例如,如果你不想替换 HashTable 中已经存在的内容,你可能会编写如下代码:
java
if(!hashTable.containsKey(someKey)) {
hashTable.put(someKey, new SomeValue());
}Each individual method is thread-safe. However, another thread might add a value in between the containsKey and put calls. There are several options to fix this problem.
每个单独的方法都是线程安全的。然而,另一个线程可能在 containsKey 和 put 调用之间添加了一个值。有几种方法可以解决这个问题。
- Lock the HashTable first, and make sure all other users of the HashTable do the same--client-based locking:
- 首先锁定 HashTable,并确保 HashTable 的所有其他使用者也这样做——基于客户端的锁(client-based locking):
java
synchronized(map) {
if(!map.conainsKey(key))
map.put(key, value);
}- Wrap the HashTable in its own object and use a different API--server-based locking using an ADAPTER:
- 将 HashTable 包装在自己的对象中并使用不同的 API——使用 ADAPTER 实现基于服务器的锁(server-based locking):
java
public class WrappedHashtable<K, V> {
private Map<K, V> map = new Hashtable<K, V>();
public synchronized void putIfAbsent(K key, V value) {
if (map.containsKey(key))
map.put(key, value);
}
}- Use the thread-safe collections:
- 使用线程安全的集合:
java
ConcurrentHashMap<Integer, String> map = new ConcurrentHashMap<Integer,
String>();
map.putIfAbsent(key, value);The collections in java.util.concurrent have operations like putIfAbsent() to accommodate such operations.
java.util.concurrent 中的集合具有像 putIfAbsent() 这样的操作来支持此类操作。
DEPENDENCIES BETWEEN METHODS CAN BREAK CONCURRENT CODE 方法间的依赖可能破坏并发代码
Here is a trivial example of a way to introduce dependencies between methods:
下面是一个引入方法间依赖的简单示例:
java
public class IntegerIterator implements Iterator<Integer>
private Integer nextValue = 0;
public synchronized boolean hasNext() {
return nextValue < 100000;
}
public synchronized Integer next() {
if (nextValue == 100000)
throw new IteratorPastEndException();
return nextValue++;
}
public synchronized Integer getNextValue() {
return nextValue;
}
}Here is some code to use this IntegerIterator:
下面是使用 IntegerIterator 的代码:
java
IntegerIterator iterator = new IntegerIterator();
while(iterator.hasNext()) {
int nextValue = iterator.next();
// do something with nextValue
}If one thread executes this code, there will be no problem. But what happens if two threads attempt to share a single instance of IngeterIterator with the intent that each thread will process the values it gets, but that each element of the list is processed only once? Most of the time, nothing bad happens; the threads happily share the list, processing the elements they are given by the iterator and stopping when the iterator is complete. However, there is a small chance that, at the end of the iteration, the two threads will interfere with each other and cause one thread to go beyond the end of the iterator and throw an exception.
如果一个线程执行这段代码,没有问题。但如果两个线程试图共享一个 IntegerIterator 实例,意图是每个线程处理它获得的值,但列表中的每个元素只被处理一次,会发生什么?大多数时候,不会发生坏事;线程愉快地共享列表,处理迭代器给它们的元素,并在迭代器完成时停止。然而,有一个小概率事件,在迭代结束时,两个线程会相互干扰,导致一个线程超出迭代器末尾并抛出异常。
Here's the problem: Thread 1 asks the question hasNext(), which returns true. Thread 1 gets preempted and then Thread 2 asks the same question, which is still true. Thread 2 then calls next(), which returns a value as expected but has a side effect of making hasNext() return false. Thread 1 starts up again, thinking hasNext() is still true, and then calls next(). Even though the individual methods are synchronized, the client uses two methods.
问题在于:线程 1 询问 hasNext(),返回 true。线程 1 被抢占,然后线程 2 询问同样的问题,仍然返回 true。线程 2 接着调用 next(),按预期返回一个值,但有一个副作用——使 hasNext() 返回 false。线程 1 重新开始运行,认为 hasNext() 仍然为 true,然后调用 next()。虽然各个方法是同步的,但客户端使用了两个方法。
This is a real problem and an example of the kinds of problems that crop up in concurrent code. In this particular situation this problem is especially subtle because the only time where this causes a fault is when it happens during the final iteration of the iterator. If the threads happen to break just right, then one of the threads could go beyond the end of the iterator. This is the kind of bug that happens long after a system has been in production, and it is hard to track down.
这是一个真实的问题,是并发代码中会出现的那类问题的一个例子。在这种特定情况下,这个问题尤其微妙,因为它只在迭代器的最后一次迭代时才会导致故障。如果线程恰好在某个点被打断,其中一个线程就可能超出迭代器末尾。这类 bug 会在系统上线很长时间后才出现,而且很难追踪。
You have three options:
你有三种选择:
- Tolerate the failure.
- Solve the problem by changing the client: client-based locking
- Solve the problem by changing the server, which additionally changes the client: server-based locking
- 容忍故障。
- 通过修改客户端来解决问题:基于客户端的锁
- 通过修改服务器来解决问题,同时也修改了客户端:基于服务器的锁
Tolerate the Failure 容忍故障
Sometimes you can set things up such that the failure causes no harm. For example, the above client could catch the exception and clean up. Frankly, this is a bit sloppy. It's rather like cleaning up memory leaks by rebooting at midnight.
有时你可以做一些设置使得故障不会造成损害。例如,上面的客户端可以捕获异常并进行清理。坦率地说,这有点草率。这就像在午夜重启来清理内存泄漏一样。
Client-Based Locking 基于客户端的锁
To make IntegerIterator work correctly with multiple threads, change this client (and every other client) as follows:
为了使 IntegerIterator 在多线程环境下正确工作,按如下方式修改这个客户端(以及其他所有客户端):
java
IntegerIterator iterator = new IntegerIterator();
while (true) {
int nextValue;
synchronized (iterator) {
if (!iterator.hasNext())
break;
nextValue = iterator.next();
}
doSometingWith(nextValue);
}Each client introduces a lock via the synchronized keyword. This duplication violates the DRY principle, but it might be necessary if the code uses non-thread-safe third-party tools.
每个客户端都通过 synchronized 关键字引入了一个锁。这种重复违反了 DRY 原则,但如果代码使用了非线程安全的第三方工具,这可能是必要的。
This strategy is risky because all programmers who use the server must remember to lock it before using it and unlock it when done. Many (many!) years ago I worked on a system that employed client-based locking on a shared resource. The resource was used in hundreds of different places throughout the code. One poor programmer forgot to lock the resource in one of those places.
这种策略是有风险的,因为所有使用服务器的程序员都必须记住在使用前锁定它,使用后解锁。很多很多年前,我曾在一个系统上工作,该系统对共享资源采用了基于客户端的锁。该资源在代码中数百个不同的地方被使用。一个可怜的程序员在其中一个地方忘记了锁定资源。
The system was a multi-terminal time-sharing system running accounting software for Local 705 of the trucker's union. The computer was in a raised-floor, environment-controlled room 50 miles north of the Local 705 headquarters. At the headquarters they had dozens of data entry clerks typing union dues postings into the terminals. The terminals were connected to the computer using dedicated phone lines and 600bps half-duplex modems. (This was a very, very long time ago.)
该系统是一个多终端分时系统,为卡车司机工会 705 地方分会运行会计软件。计算机位于 705 地方分会总部以北 50 英里处的一个架空地板、环境受控的机房里。在总部,他们有数十名数据录入员在终端上输入工会会费记录。终端通过专用电话线和 600bps 半双工调制解调器连接到计算机。(这是很久很久以前的事了。)
About once per day, one of the terminals would "lock up." There was no rhyme or reason to it. The lock up showed no preference for particular terminals or particular times. It was as though there were someone rolling dice choosing the time and terminal to lock up. Sometimes more than one terminal would lock up. Sometimes days would go by without any lock-ups.
大约每天一次,某个终端会"死锁"。毫无规律可循。死锁不偏爱特定的终端或特定的时间。就好像有人在掷骰子来选择死锁的时间和终端。有时不止一个终端会死锁。有时好几天都不会有任何死锁。
At first the only solution was a reboot. But reboots were tough to coordinate. We had to call the headquarters and get everyone to finish what they were doing on all the terminals. Then we could shut down and restart. If someone was doing something important that took an hour or two, the locked up terminal simply had to stay locked up.
最初唯一的解决方案是重启。但重启很难协调。我们不得不打电话给总部,让所有人在所有终端上完成他们正在做的事情。然后我们才能关机重启。如果有人正在做重要的事情需要一两个小时,那死锁的终端就只能继续死锁着。
After a few weeks of debugging we found that the cause was a ring-buffer counter that had gotten out of sync with its pointer. This buffer controlled output to the terminal. The pointer value indicated that the buffer was empty, but the counter said it was full. Because it was empty, there was nothing to display; but because it was also full, nothing could be added to the buffer to be displayed on the screen.
经过几周的调试,我们发现原因是环形缓冲区计数器与其指针不同步。这个缓冲区控制着终端的输出。指针值表明缓冲区是空的,但计数器说它是满的。因为它是空的,所以没有东西可显示;但因为它又是满的,所以无法向缓冲区添加内容来显示在屏幕上。
So we knew why the terminals were locking, but we didn't know why the ring buffer was getting out of sync. So we added a hack to work around the problem. It was possible to read the front panel switches on the computer. (This was a very, very, very long time ago.) We wrote a little trap function that detected when one of these switches was thrown and then looked for a ring buffer that was both empty and full. If one was found, it reset that buffer to empty. Voila! The locked-up terminal(s) started displaying again.
所以我们知道了终端死锁的原因,但不知道为什么环形缓冲区会失去同步。所以我们添加了一个 hack 来绕过这个问题。可以读取计算机前面板上的开关。(这是非常非常久以前的事了。)我们编写了一个小的陷阱函数,检测这些开关何时被触发,然后寻找既空又满的环形缓冲区。如果找到了,就将该缓冲区重置为空。瞧!死锁的终端又开始显示了。
So now we didn't have to reboot the system when a terminal locked up. The Local would simply call us and tell us we had a lock-up, and then we just walked into the computer room and flicked a switch.
这样当终端死锁时我们就不用重启系统了。地方分会只需要打电话告诉我们发生了死锁,然后我们走进机房拨动一个开关就行了。
Of course sometimes they worked on the weekends, and we didn't. So we added a function to the scheduler that checked all the ring buffers once per minute and reset any that were both empty and full. This caused the displays to unclog before the Local could even get on the phone.
当然,有时他们周末工作而我们不工作。所以我们在调度器中添加了一个函数,每分钟检查一次所有的环形缓冲区,并重置任何既空又满的缓冲区。这样在地方分会打电话之前,显示就已经恢复了。
It was several more weeks of poring over page after page of monolithic assembly language code before we found the culprit. We had done the math and calculated that the frequency of the lock-ups was consistent with a single unprotected use of the ring buffer. So all we had to do was find that one faulty usage. Unfortunately, this was so very long ago that we didn't have search tools or cross references or any other kind of automated help. We simply had to pore over listings.
又过了好几周,我们一页一页地翻阅庞大的汇编语言代码,才找到了罪魁祸首。我们做了数学计算,发现死锁的频率与环形缓冲区的一次未受保护的使用是一致的。所以我们只需要找到那个错误的用法。不幸的是,那是很久以前的事了,我们没有搜索工具或交叉引用或任何其他类型的自动化帮助。我们只能一页一页地翻阅程序清单。
I learned an important lesson that cold Chicago winter of 1971. Client-based locking really blows.
在 1971 年芝加哥那个寒冷的冬天,我学到了重要的一课。基于客户端的锁真的很糟糕。
Server-Based Locking 基于服务器的锁
The duplication can be removed by making the following changes to IntegerIterator:
可以通过对 IntegerIterator 进行以下修改来消除重复:
java
public class IntegerIteratorServerLocked {
private Integer nextValue = 0;
public synchronized Integer getNextOrNull() {
if (nextValue < 100000)
return nextValue++;
else
return null;
}
}And the client code changes as well:
客户端代码也相应改变:
java
while (true) {
Integer nextValue = iterator.getNextOrNull();
if (next == null)
break;
// do something with nextValue
}In this case we actually change the API of our class to be multithread aware.3 The client needs to perform a null check instead of checking hasNext().
在这种情况下,我们实际上将类的 API 更改为多线程感知的^[3]。客户端需要执行 null 检查而不是检查 hasNext()。
- In fact, the Iterator interface is inherently not thread-safe. It was never designed to be used by multiple threads, so this should come as no surprise.
[3] 事实上,Iterator 接口天生就不是线程安全的。它从未被设计为供多线程使用,所以这不应该让人感到意外。
In general you should prefer server-based locking for these reasons:
通常你应该优先选择基于服务器的锁,原因如下:
- It reduces repeated code--Client-based locking forces each client to lock the server properly. By putting the locking code into the server, clients are free to use the object and not worry about writing additional locking code.
- It allows for better performance--You can swap out a thread-safe server for a non-thread safe one in the case of single-threaded deployment, thereby avoiding all overhead.
- It reduces the possibility of error--All it takes is for one programmer to forget to lock properly.
- It enforces a single policy--The policy is in one place, the server, rather than many places, each client.
- It reduces the scope of the shared variables--The client is not aware of them or how they are locked. All of that is hidden in the server. When things break, the number of places to look is smaller.
- 它减少了重复代码——基于客户端的锁迫使每个客户端正确地锁定服务器。通过将锁定代码放入服务器,客户端可以自由使用对象而无需担心编写额外的锁定代码。
- 它允许更好的性能——在单线程部署的情况下,你可以将线程安全的服务器换成非线程安全的服务器,从而避免所有开销。
- 它减少了出错的可能性——只需要一个程序员忘记正确锁定就够了。
- 它强制执行单一策略——策略在一个地方(服务器),而不是多个地方(每个客户端)。
- 它减少了共享变量的作用域——客户端不知道它们或它们是如何被锁定的。所有这些都隐藏在服务器中。当出现问题时,需要查找的地方更少。
What if you do not own the server code?
如果你没有服务器代码的所有权怎么办?
- Use an ADAPTER to change the API and add locking
- 使用 ADAPTER 来更改 API 并添加锁
java
public class ThreadSafeIntegerIterator {
private IntegerIterator iterator = new IntegerIterator();
public synchronized Integer getNextOrNull() {
if(iterator.hasNext())
return iterator.next();
return null;
}
}- OR better yet, use the thread-safe collections with extended interfaces
- 或者更好的是,使用具有扩展接口的线程安全集合
INCREASING THROUGHPUT 提高吞吐量
Let's assume that we want to go out on the net and read the contents of a set of pages from a list of URLs. As each page is read, we will parse it to accumulate some statistics. Once all the pages are read, we will print a summary report.
假设我们想从网络上读取一组 URL 列表中各个页面的内容。每读取一个页面,我们将解析它以累积一些统计数据。一旦所有页面读取完毕,我们将打印一份汇总报告。
The following class returns the contents of one page, given a URL.
下面的类根据给定的 URL 返回一个页面的内容。
java
public class PageReader {
//...
public String getPageFor(String url) {
HttpMethod method = new GetMethod(url);
try {
httpClient.executeMethod(method);
String response = method.getResponseBodyAsString();
return response;
} catch (Exception e) {
handle(e);
} finally {
method.releaseConnection();
}
}
}The next class is the iterator that provides the contents of the pages based on an iterator of URLs:
下一个类是基于 URL 迭代器提供页面内容的迭代器:
java
public class PageIterator {
private PageReader reader;
private URLIterator urls;
public PageIterator(PageReader reader, URLIterator urls) {
this.urls = urls;
this.reader = reader;
}
public synchronized String getNextPageOrNull() {
if (urls.hasNext())
getPageFor(urls.next());
else
return null;
}
public String getPageFor(String url) {
return reader.getPageFor(url);
}
}An instance of the PageIterator can be shared between many different threads, each one using it's own instance of the PageReader to read and parse the pages it gets from the iterator.
PageIterator 的一个实例可以被许多不同的线程共享,每个线程使用自己的 PageReader 实例来读取和解析从迭代器获得的页面。
Notice that we've kept the synchronized block very small. It contains just the critical section deep inside the PageIterator. It is always better to synchronize as little as possible as opposed to synchronizing as much as possible.
注意我们将 synchronized 块保持得很小。它只包含 PageIterator 深处的临界区。同步的代码越少越好,而不是越多越好。
Single-Thread Calculation of Throughput 单线程吞吐量计算
Now lets do some simple calculations. For the purpose of argument, assume the following:
现在让我们做一些简单的计算。为了便于讨论,假设如下:
- I/O time to retrieve a page (average): 1 second
- Processing time to parse page (average): .5 seconds
- I/O requires 0 percent of the CPU while processing requires 100 percent.
- 检索页面的 I/O 时间(平均):1 秒
- 解析页面的处理时间(平均):0.5 秒
- I/O 不需要 CPU,而处理需要 100% 的 CPU。
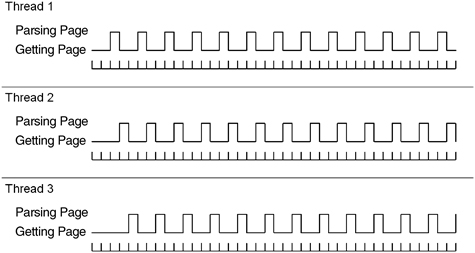
For N pages being processed by a single thread, the total execution time is 1.5 seconds * N. Figure A-1 shows a snapshot of 13 pages or about 19.5 seconds.
对于由单个线程处理的 N 个页面,总执行时间为 1.5 秒 * N。图 A-1 展示了 13 个页面的快照,大约 19.5 秒。
图 A-1 单线程

Multithread Calculation of Throughput 多线程吞吐量计算
If it is possible to retrieve pages in any order and process the pages independently, then it is possible to use multiple threads to increase throughput. What happens if we use three threads? How many pages can we acquire in the same time?
如果可以按任意顺序检索页面并独立处理页面,那么就可以使用多线程来提高吞吐量。如果我们使用三个线程会怎样?在相同时间内我们能获取多少页面?
As you can see in Figure A-2, the multithreaded solution allows the process-bound parsing of the pages to overlap with the I/O-bound reading of the pages. In an idealized world this means that the processor is fully utilized. Each one-second page read is overlapped with two parses. Thus, we can process two pages per second, which is three times the throughput of the single-threaded solution.
如图 A-2 所示,多线程解决方案允许处理器密集型的页面解析与 I/O 密集型的页面读取重叠。在理想情况下,这意味着处理器被充分利用。每次一秒的页面读取与两次解析重叠。因此,我们可以每秒处理两个页面,这是单线程解决方案吞吐量的三倍。
图 A-2 三个并发线程
DEADLOCK 死锁
Imagine a Web application with two shared resource pools of some finite size:
想象一个具有两个有限大小共享资源池的 Web 应用程序:
- A pool of database connections for local work in process storage
- A pool of MQ connections to a master repository
- 一个用于本地在制品存储的数据库连接池
- 一个连接到主仓库的 MQ 连接池
Assume there are two operations in this application, create and update:
假设这个应用程序中有两个操作:create 和 update:
- Create--Acquire connection to master repository and database. Talk to service master repository and then store work in local work in process database.
- Update--Acquire connection to database and then master repository. Read from work in process database and then send to the master repository
- Create——获取到主仓库和数据库的连接。与服务主仓库通信,然后将工作存储到本地在制品数据库。
- Update——获取到数据库然后是主仓库的连接。从在制品数据库读取,然后发送到主仓库。
What happens when there are more users than the pool sizes? Consider each pool has a size of ten.
当用户数量超过池大小时会发生什么?假设每个池的大小为十。
- Ten users attempt to use create, so all ten database connections are acquired, and each thread is interrupted after acquiring a database connection but before acquiring a connection to the master repository.
- Ten users attempt to use update, so all ten master repository connections are acquired, and each thread is interrupted after acquiring the master repository but before acquiring a database connection.
- Now the ten "create" threads must wait to acquire a master repository connection, but the ten "update" threads must wait to acquire a database connection.
- Deadlock. The system never recovers.
- 十个用户尝试使用 create,所以所有十个数据库连接都被获取,每个线程在获取数据库连接之后但在获取主仓库连接之前被中断。
- 十个用户尝试使用 update,所以所有十个主仓库连接都被获取,每个线程在获取主仓库连接之后但在获取数据库连接之前被中断。
- 现在十个"create"线程必须等待获取主仓库连接,但十个"update"线程必须等待获取数据库连接。
- 死锁。系统永远无法恢复。
This might sound like an unlikely situation, but who wants a system that freezes solid every other week? Who wants to debug a system with symptoms that are so difficult to reproduce? This is the kind of problem that happens in the field, then takes weeks to solve.
这听起来可能不太可能发生,但谁想要一个每隔一周就完全冻结的系统呢?谁想要调试一个症状如此难以重现的系统?这就是那种在生产环境中发生、然后需要数周才能解决的问题。
A typical "solution" is to introduce debugging statements to find out what is happening. Of course, the debug statements change the code enough so that the deadlock happens in a different situation and takes months to again occur.4
典型的"解决方案"是引入调试语句来了解正在发生的事情。当然,调试语句对代码的修改足以使死锁发生在不同的情况下,需要数月才会再次出现^[4]。
- For example, someone adds some debugging output and the problem "disappears." The debugging code "fixes" the problem so it remains in the system.
[4] 例如,某人添加了一些调试输出,问题就"消失"了。调试代码"修复"了问题,所以它留在了系统中。
To really solve the problem of deadlock, we need to understand what causes it. There are four conditions required for deadlock to occur:
要真正解决死锁问题,我们需要了解它的成因。死锁发生需要四个条件:
- Mutual exclusion
- Lock & wait
- No preemption
- Circular wait
- 互斥(Mutual exclusion)
- 锁与等待(Lock & wait)
- 不可抢占(No preemption)
- 循环等待(Circular wait)
Mutual Exclusion 互斥
Mutual exclusion occurs when multiple threads need to use the same resources and those resources
当多个线程需要使用相同的资源且这些资源
- Cannot be used by multiple threads at the same time.
- Are limited in number.
- 不能被多个线程同时使用。
- 数量有限。
A common example of such a resource is a database connection, a file open for write, a record lock, or a semaphore.
这类资源的一个常见例子是数据库连接、打开用于写入的文件、记录锁或信号量。
Lock & Wait 锁与等待
Once a thread acquires a resource, it will not release the resource until it has acquired all of the other resources it requires and has completed its work.
一旦线程获取了一个资源,它将不会释放该资源,直到它获取了所需的所有其他资源并完成了工作。
No Preemption 不可抢占
One thread cannot take resources away from another thread. Once a thread holds a resource, the only way for another thread to get it is for the holding thread to release it.
一个线程不能从另一个线程手中夺取资源。一旦一个线程持有资源,另一个线程获取它的唯一方式是持有线程释放它。
Circular Wait 循环等待
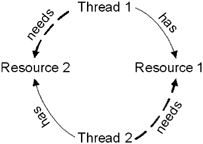
This is also referred to as the deadly embrace. Imagine two threads, T1 and T2, and two resources, R1 and R2. T1 has R1, T2 has R2. T1 also requires R2, and T2 also requires R1. This gives something like Figure A-3:
这也被称为致命拥抱(deadly embrace)。想象两个线程 T1 和 T2,以及两个资源 R1 和 R2。T1 持有 R1,T2 持有 R2。T1 还需要 R2,T2 还需要 R1。这就像图 A-3:
图 A-3
All four of these conditions must hold for deadlock to be possible. Break any one of these conditions and deadlock is not possible.
这四个条件必须同时成立,死锁才可能发生。打破任何一个条件,死锁就不可能发生。
Breaking Mutual Exclusion 打破互斥
One strategy for avoiding deadlock is to sidestep the mutual exclusion condition. You might be able to do this by
避免死锁的一种策略是规避互斥条件。你可以通过以下方式做到:
- Using resources that allow simultaneous use, for example, AtomicInteger.
- Increasing the number of resources such that it equals or exceeds the number of competing threads.
- Checking that all your resources are free before seizing any.
- 使用允许同时使用的资源,例如 AtomicInteger。
- 增加资源数量,使其等于或超过竞争线程的数量。
- 在抢占任何资源之前检查所有资源是否空闲。
Unfortunately, most resources are limited in number and don't allow simultaneous use. And it's not uncommon for the identity of the second resource to be predicated on the results of operating on the first. But don't be discouraged; there are three conditions left.
不幸的是,大多数资源数量有限且不允许同时使用。而且第二个资源的身份取决于对第一个资源操作的结果,这种情况并不少见。但不要灰心;还有三个条件可以打破。
Breaking Lock & Wait 打破锁与等待
You can also eliminate deadlock if you refuse to wait. Check each resource before you seize it, and release all resources and start over if you run into one that's busy.
如果你拒绝等待,也可以消除死锁。在抢占每个资源之前先检查它,如果遇到忙的资源,就释放所有资源并重新开始。
This approach introduces several potential problems:
这种方法引入了几个潜在问题:
- Starvation--One thread keeps being unable to acquire the resources it needs (maybe it has a unique combination of resources that seldom all become available).
- Livelock--Several threads might get into lockstep and all acquire one resource and then release one resource, over and over again. This is especially likely with simplistic CPU scheduling algorithms (think embedded devices or simplistic hand-written thread balancing algorithms).
- 饥饿(Starvation)——一个线程持续无法获取所需的资源(也许它需要的资源组合很少同时可用)。
- 活锁(Livelock)——几个线程可能步调一致地反复获取一个资源然后释放一个资源。这在简单的 CPU 调度算法中尤其可能发生(想想嵌入式设备或简单的手写线程平衡算法)。
Both of these can cause poor throughput. The first results in low CPU utilization, whereas the second results in high and useless CPU utilization.
这两种情况都会导致吞吐量低下。前者导致 CPU 利用率低,后者导致 CPU 利用率高但无用。
As inefficient as this strategy sounds, it's better than nothing. It has the benefit that it can almost always be implemented if all else fails.
尽管这种策略听起来效率低下,但总比没有好。它的好处是,如果其他方法都失败了,几乎总能实现。
Breaking Preemption 打破不可抢占
Another strategy for avoiding deadlock is to allow threads to take resources away from other threads. This is usually done through a simple request mechanism. When a thread discovers that a resource is busy, it asks the owner to release it. If the owner is also waiting for some other resource, it releases them all and starts over.
另一种避免死锁的策略是允许线程从其他线程手中夺取资源。这通常通过简单的请求机制实现。当一个线程发现资源忙时,它请求拥有者释放它。如果拥有者也在等待其他资源,它就释放所有资源并重新开始。
This is similar to the previous approach but has the benefit that a thread is allowed to wait for a resource. This decreases the number of startovers. Be warned, however, that managing all those requests can be tricky.
这类似于前一种方法,但好处是线程可以等待资源。这减少了重新开始的次数。但请注意,管理所有这些请求可能很棘手。
Breaking Circular Wait 打破循环等待
This is the most common approach to preventing deadlock. For most systems it requires no more than a simple convention agreed to by all parties.
这是防止死锁最常见的方法。对于大多数系统,它只需要各方达成一个简单的约定。
In the example above with Thread 1 wanting both Resource 1 and Resource 2 and Thread 2 wanting both Resource 2 and then Resource 1, simply forcing both Thread 1 and Thread 2 to allocate resources in the same order makes circular wait impossible.
在上面的例子中,线程 1 需要资源 1 和资源 2,线程 2 需要资源 2 然后是资源 1,只需强制线程 1 和线程 2 按相同顺序分配资源,就使循环等待不可能发生。
More generally, if all threads can agree on a global ordering of resources and if they all allocate resources in that order, then deadlock is impossible. Like all the other strategies, this can cause problems:
更一般地说,如果所有线程能就资源的全局排序达成一致,并且都按该顺序分配资源,那么死锁就不可能发生。与所有其他策略一样,这可能导致问题:
- The order of acquisition might not correspond to the order of use; thus a resource acquired at the start might not be used until the end. This can cause resources to be locked longer than strictly necessary.
- Sometimes you cannot impose an order on the acquisition of resources. If the ID of the second resource comes from an operation performed on the first, then ordering is not feasible.
- 获取顺序可能与使用顺序不对应;因此,开始获取的资源可能直到最后才使用。这可能导致资源被锁定的时间超过严格必要的时间。
- 有时你无法对资源的获取施加顺序。如果第二个资源的 ID 来自对第一个资源执行的操作,那么排序就不可行。
So there are many ways to avoid deadlock. Some lead to starvation, whereas others make heavy use of the CPU and reduce responsiveness. TANSTAAFL!5
所以有很多方法可以避免死锁。有些导致饥饿,有些则大量使用 CPU 并降低响应性。TANSTAAFL!^[5]
- There ain't no such thing as a free lunch.
[5] 天下没有免费的午餐。
Isolating the thread-related part of your solution to allow for tuning and experimentation is a powerful way to gain the insights needed to determine the best strategies.
将解决方案中与线程相关的部分隔离出来,以允许调优和实验,这是获得确定最佳策略所需洞察力的有力方式。
TESTING MULTITHREADED CODE 测试多线程代码
How can we write a test to demonstrate the following code is broken?
我们如何编写测试来证明下面的代码是有问题的?
java
01: public class ClassWithThreadingProblem {
02: int nextId;
03:
04: public int takeNextId() {
05: return nextId++;
06: }
07:}Here's a description of a test that will prove the code is broken:
下面是一个测试的描述,它将证明代码是有问题的:
- Remember the current value of nextId.
- Create two threads, both of which call takeNextId() once.
- Verify that nextId is two more than what we started with.
- Run this until we demonstrate that nextId was only incremented by one instead of two.
- 记住 nextId 的当前值。
- 创建两个线程,都各调用一次 takeNextId()。
- 验证 nextId 比我们开始时多了二。
- 运行直到我们证明 nextId 只增加了一而不是二。
Listing A-2 shows such a test:
代码清单 A-2 展示了这样一个测试:
代码清单 A-2 ClassWithThreadingProblemTest.java
java
01: package example;
02:
03: import static org.junit.Assert.fail;
04:
05: import org.junit.Test;
06:
07: public class ClassWithThreadingProblemTest {
08: @Test
09: public void twoThreadsShouldFailEventually() throws Exception {
10: final ClassWithThreadingProblem classWithThreadingProblem
= new ClassWithThreadingProblem();
11:
12: Runnable runnable = new Runnable() {
13: public void run() {
14: classWithThreadingProblem.takeNextId();
15: }
16: };
17:
18: for (int i = 0; i < 50000; ++i) {
19: int startingId = classWithThreadingProblem.lastId;
20: int expectedResult = 2 + startingId;
21:
22: Thread t1 = new Thread(runnable);
23: Thread t2 = new Thread(runnable);
24: t1.start();
25: t2.start();
26: t1.join();
27: t2.join();
28:
29: int endingId = classWithThreadingProblem.lastId;
30:
31: if (endingId != expectedResult)
32: return;
33: }
34:
35: fail("Should have exposed a threading issue but it did not.");
36: }
37: }

This test certainly sets up the conditions for a concurrent update problem. However, the problem occurs so infrequently that the vast majority of times this test won't detect it.
这个测试确实设置了并发更新问题的条件。然而,问题发生得如此不频繁,以至于绝大多数时候这个测试不会检测到它。
Indeed, to truly detect the problem we need to set the number of iterations to over one million. Even then, in ten executions with a loop count of 1,000,000, the problem occurred only once. That means we probably ought to set the iteration count to well over one hundred million to get reliable failures. How long are we prepared to wait?
事实上,要真正检测到问题,我们需要将迭代次数设置为超过一百万次。即便如此,在循环次数为 1,000,000 的十次执行中,问题只发生了一次。这意味着我们可能应该将迭代次数设置为远超过一亿次才能获得可靠的失败。我们要等多久?
Even if we tuned the test to get reliable failures on one machine, we'll probably have to retune the test with different values to demonstrate the failure on another machine, operating system, or version of the JVM.
即使我们调优了测试以在一台机器上获得可靠的失败,我们可能还需要在另一台机器、操作系统或 JVM 版本上用不同的值重新调优测试来证明失败。
And this is a simple problem. If we cannot demonstrate broken code easily with this problem, how will we ever detect truly complex problems?
而这还是一个简单的问题。如果我们不能用这个问题轻松地证明代码有问题,我们又如何检测真正复杂的问题呢?
So what approaches can we take to demonstrate this simple failure? And, more importantly, how can we write tests that will demonstrate failures in more complex code? How will we be able to discover if our code has failures when we do not know where to look?
那么我们可以采取什么方法来证明这个简单的失败?更重要的是,我们如何编写测试来证明更复杂代码中的失败?当我们不知道去哪里找时,我们如何发现代码中是否存在失败?
Here are a few ideas:
这里有一些想法:
- Monte Carlo Testing. Make tests flexible, so they can be tuned. Then run the test over and over--say on a test server--randomly changing the tuning values. If the tests ever fail, the code is broken. Make sure to start writing those tests early so a continuous integration server starts running them soon. By the way, make sure you carefully log the conditions under which the test failed.
- 蒙特卡洛测试(Monte Carlo Testing)。使测试灵活可调。然后反复运行测试——比如在测试服务器上——随机改变调优值。如果测试失败了,代码就有问题。确保尽早开始编写这些测试,以便持续集成服务器尽快开始运行它们。顺便说一句,确保你仔细记录测试失败时的条件。
- Run the test on every one of the target deployment platforms. Repeatedly. Continuously. The longer the tests run without failure, the more likely that
- 在每个目标部署平台上运行测试。反复地。持续地。测试运行得越久没有失败,就越可能
– The production code is correct or
– 生产代码是正确的,或者
– The tests aren't adequate to expose problems.
– 测试不足以暴露问题。
- Run the tests on a machine with varying loads. If you can simulate loads close to a production environment, do so.
- 在不同负载的机器上运行测试。如果你能模拟接近生产环境的负载,就这样做。
Yet, even if you do all of these things, you still don't stand a very good chance of finding threading problems with your code. The most insidious problems are the ones that have such a small cross section that they only occur once in a billion opportunities. Such problems are the terror of complex systems.
然而,即使你做了所有这些,你仍然不太可能发现代码中的线程问题。最阴险的问题是那些截面如此之小以至于十亿次机会中只发生一次的问题。这类问题是复杂系统的噩梦。
TOOL SUPPORT FOR TESTING THREAD-BASED CODE 测试线程代码的工具支持
IBM has created a tool called ConTest.6 It instruments classes to make it more likely that non-thread-safe code fails.
IBM 创建了一个名为 ConTest 的工具^[6]。它对类进行插桩,使非线程安全的代码更可能失败。
[6] http://www.haifa.ibm.com/projects/verification/contest/index.html
We do not have any direct relationship with IBM or the team that developed ConTest. A colleague of ours pointed us to it. We noticed vast improvement in our ability to find threading issues after a few minutes of using it.
我们与 IBM 或开发 ConTest 的团队没有任何直接关系。一位同事把它介绍给了我们。我们注意到在使用几分钟后,发现线程问题的能力有了巨大的提升。
Here's an outline of how to use ConTest:
下面是使用 ConTest 的概要:
- Write tests and production code, making sure there are tests specifically designed to simulate multiple users under varying loads, as mentioned above.
- Instrument test and production code with ConTest.
- Run the tests.
- 编写测试和生产代码,确保有专门设计的测试来模拟不同负载下的多个用户,如上所述。
- 使用 ConTest 对测试和生产代码进行插桩。
- 运行测试。
When we instrumented code with ConTest, our success rate went from roughly one failure in ten million iterations to roughly one failure in thirty iterations. Here are the loop values for several runs of the test after instrumentation: 13, 23, 0, 54, 16, 14, 6, 69, 107, 49, 2. So clearly the instrumented classes failed much earlier and with much greater reliability.
当我们使用 ConTest 对代码进行插桩后,我们的成功率从大约每千万次迭代一次失败变为大约每三十次迭代一次失败。以下是插桩后几次测试运行的循环值:13、23、0、54、16、14、6、69、107、49、2。所以很明显,插桩后的类失败得更早、更可靠。
CONCLUSION 结论
This chapter has been a very brief sojourn through the large and treacherous territory of concurrent programming. We barely scratched the surface. Our emphasis here was on disciplines to help keep concurrent code clean, but there is much more you should learn if you are going to be writing concurrent systems. We recommend you start with Doug Lea's wonderful book Concurrent Programming in Java: Design Principles and Patterns.7
本章只是对并发编程这片广阔而险峻领域的一次非常短暂的涉足。我们只是触及了皮毛。我们在这里的重点是帮助保持并发代码整洁的规范,但如果你要编写并发系统,还有很多东西需要学习。我们建议你从 Doug Lea 的精彩著作《Concurrent Programming in Java: Design Principles and Patterns》开始^[7]。
- See [Lea99] p. 191.
[7] 参见 [Lea99] 第 191 页。
In this chapter we talked about concurrent update, and the disciplines of clean synchronization and locking that can prevent it. We talked about how threads can enhance the throughput of an I/O-bound system and showed the clean techniques for achieving such improvements. We talked about deadlock and the disciplines for preventing it in a clean way. Finally, we talked about strategies for exposing concurrent problems by instrumenting your code.
在本章中,我们讨论了并发更新以及可以防止它的整洁同步和锁定规范。我们讨论了线程如何提高 I/O 密集型系统的吞吐量,并展示了实现这种改进的整洁技术。我们讨论了死锁以及以整洁方式防止死锁的规范。最后,我们讨论了通过对代码插桩来暴露并发问题的策略。
TUTORIAL: FULL CODE EXAMPLES 教程:完整代码示例
Client/Server Nonthreaded 非线程化的客户端/服务器
代码清单 A-3 Server.java
java
package com.objectmentor.clientserver.nonthreaded;
import java.io.IOException;
import java.net.ServerSocket;
import java.net.Socket;
import java.net.SocketException;
import common.MessageUtils;
public class Server implements Runnable {
ServerSocket serverSocket;
volatile boolean keepProcessing = true;
public Server(int port, int millisecondsTimeout) throws IOException {
serverSocket = new ServerSocket(port);
serverSocket.setSoTimeout(millisecondsTimeout);
}
public void run() {
System.out.printf("Server Starting\n");
while (keepProcessing) {
try {
System.out.printf("accepting client\n");
Socket socket = serverSocket.accept();
System.out.printf("got client\n");
process(socket);
} catch (Exception e) {
handle(e);
}
}
}
private void handle(Exception e) {
if (!(e instanceof SocketException)) {
e.printStackTrace();
}
}
public void stopProcessing() {
keepProcessing = false;
closeIgnoringException(serverSocket);
}
void process(Socket socket) {
if (socket == null)
return;
try {
System.out.printf("Server: getting message\n");
String message = MessageUtils.getMessage(socket);
System.out.printf("Server: got message: %s\n", message);
Thread.sleep(1000);
System.out.printf("Server: sending reply: %s\n", message);
MessageUtils.sendMessage(socket, "Processed: " + message);
System.out.printf("Server: sent\n");
closeIgnoringException(socket);
} catch (Exception e) {
e.printStackTrace();
}
}
private void closeIgnoringException(Socket socket) {
if (socket != null)
try {
socket.close();
} catch (IOException ignore) {
}
}
private void closeIgnoringException(ServerSocket serverSocket) {
if (serverSocket != null)
try {
serverSocket.close();
} catch (IOException ignore) {
}
}
}代码清单 A-4 ClientTest.java
java
package com.objectmentor.clientserver.nonthreaded;
import java.io.IOException;
import java.net.Socket;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import common.MessageUtils;
public class ClientTest {
private static final int PORT = 8009;
private static final int TIMEOUT = 2000;
Server server;
Thread serverThread;
@Before
public void createServer() throws Exception {
try {
server = new Server(PORT, TIMEOUT);
serverThread = new Thread(server);
serverThread.start();
} catch (Exception e) {
e.printStackTrace(System.err);
throw e;
}
}
@After
public void shutdownServer() throws InterruptedException {
if (server != null) {
server.stopProcessing();
serverThread.join();
}
}
class TrivialClient implements Runnable {
int clientNumber;
TrivialClient(int clientNumber) {
this.clientNumber = clientNumber;
}
public void run() {
try {
connectSendReceive(clientNumber);
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Test(timeout = 10000)
public void shouldRunInUnder10Seconds() throws Exception {
Thread[] threads = new Thread[10];
for (int i = 0; i < threads.length; ++i) {
threads[i] = new Thread(new TrivialClient(i));
threads[i].start();
}
for (int i = 0; i < threads.length; ++i) {
threads[i].join();
}
}
private void connectSendReceive(int i) throws IOException {
System.out.printf("Client %2d: connecting\n", i);
Socket socket = new Socket("localhost", PORT);
System.out.printf("Client %2d: sending message\n", i);
MessageUtils.sendMessage(socket, Integer.toString(i));
System.out.printf("Client %2d: getting reply\n", i);
MessageUtils.getMessage(socket);
System.out.printf("Client %2d: finished\n", i);
socket.close();
}
}代码清单 A-5 MessageUtils.java
java
package common;
import java.io.IOException;
import java.io.InputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.OutputStream;
import java.net.Socket;
public class MessageUtils {
public static void sendMessage(Socket socket, String message)
throws IOException {
OutputStream stream = socket.getOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(stream);
oos.writeUTF(message);
oos.flush();
}
public static String getMessage(Socket socket) throws IOException {
InputStream stream = socket.getInputStream();
ObjectInputStream ois = new ObjectInputStream(stream);
return ois.readUTF();
}
}Client/Server Using Threads 使用线程的客户端/服务器
Changing the server to use threads simply requires a change to the process message (new lines are emphasized to stand out):
将服务器改为使用线程只需修改 process 消息(新增行已突出显示):
java
void process(final Socket socket) {
if (socket == null)
return;
Runnable clientHandler = new Runnable() {
public void run() {
try {
System.out.printf("Server: getting message\n");
String message = MessageUtils.getMessage(socket);
System.out.printf("Server: got message: %s\n", message);
Thread.sleep(1000);
System.out.printf("Server: sending reply: %s\n", message);
MessageUtils.sendMessage(socket, "Processed: " + message);
System.out.printf("Server: sent\n");
closeIgnoringException(socket);
} catch (Exception e) {
e.printStackTrace();
}
}
};
Thread clientConnection = new Thread(clientHandler);
clientConnection.start();
}