Appearance
第 8 章 Boundaries 边界
by James Grenning
We seldom control all the software in our systems. Sometimes we buy third-party packages or use open source. Other times we depend on teams in our own company to produce components or subsystems for us. Somehow we must cleanly integrate this foreign code with our own. In this chapter we look at practices and techniques to keep the boundaries of our software clean.
我们很少控制系统中的全部软件。有时我们购买第三方程序包或使用开放源代码,有时我们依靠公司中其他团队打造组件或子系统。不管是哪种情况,我们都得将外来代码干净利落地整合进自己的代码中。本章将介绍一些保持软件边界整洁的实践手段和技巧。
8.1 USING THIRD-PARTY CODE 使用第三方代码
There is a natural tension between the provider of an interface and the user of an interface. Providers of third-party packages and frameworks strive for broad applicability so they can work in many environments and appeal to a wide audience. Users, on the other hand, want an interface that is focused on their particular needs. This tension can cause problems at the boundaries of our systems.
在接口提供者和使用者之间,存在与生俱来的张力。第三方程序包和框架提供者追求普适性,这样就能在多个环境中工作,吸引广泛的用户。而使用者则想要集中满足特定需求的接口。这种张力会导致系统边界上出现问题。
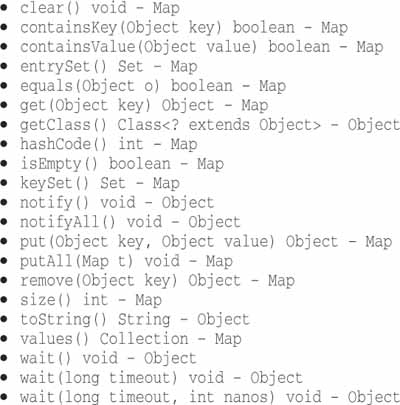
Let’s look at java.util.Map as an example. As you can see by examining Figure 8-1, Maps have a very broad interface with plenty of capabilities. Certainly this power and flexibility is useful, but it can also be a liability. For instance, our application might build up a Map and pass it around. Our intention might be that none of the recipients of our Map delete anything in the map. But right there at the top of the list is the clear() method. Any user of the Map has the power to clear it. Or maybe our design convention is that only particular types of objects can be stored in the Map, but Maps do not reliably constrain the types of objects placed within them. Any determined user can add items of any type to any Map.
以 java.util.Map 为例。如你在表 8-1 中所见,Map 有着广阔的接口和丰富的功能。当然,这种力量和灵活性很有用,但也要付出代价。比如,应用程序可能构造一个 Map 对象并传递它。我们的初衷可能是 Map 对象的所有接收者都不要删除映射图中的任何东西。但表 8-1 的顶端却正好有一个 clear( )方法。Map 的任何使用者都能清除映射图。或许设计惯例是 Map 中只能保存特定的类型,但 Map 并不会可靠地约束存于其中的对象的类型。使用者可随意往 Map 中塞入任何类型的条目。
Figure 8-1 The methods of Map
If our application needs a Map of Sensors, you might find the sensors set up like this:
如果你的应用程序需要一个包容 Sensor 类对象的 Map 映射图,大概会是这样:
java
Map sensors = new HashMap();Then, when some other part of the code needs to access the sensor, you see this code:
当代码的其他部分需要访问这些 sensor,就会有这行代码:
java
Sensor s = (Sensor)sensors.get(sensorId );We don’t just see it once, but over and over again throughout the code. The client of this code carries the responsibility of getting an Object from the Map and casting it to the right type. This works, but it’s not clean code. Also, this code does not tell its story as well as it could. The readability of this code can be greatly improved by using generics, as shown below:
这行代码一再出现。代码的调用端承担了从 Map 中取得对象并将其转换为正确类型的职责。行倒是行,却并非整洁的代码。而且,这行代码并未说明自己的用途。通过对泛型的使用,这段代码可读性可以大大提高,如下所示:
java
Map<Sensor> sensors = new HashMap<Sensor>();
…
Sensor s = sensors.get(sensorId );However, this doesn’t solve the problem that Map<Sensor> provides more capability than we need or want.
不过,
Map<Sensor>提供了超出所需/所愿的功能的问题,仍未得到解决。
Passing an instance of Map<Sensor> liberally around the system means that there will be a lot of places to fix if the interface to Map ever changes. You might think such a change to be unlikely, but remember that it changed when generics support was added in Java 5. Indeed, we’ve seen systems that are inhibited from using generics because of the sheer magnitude of changes needed to make up for the liberal use of Maps.
在系统中不受限制地传递
Map<Sensor>的实体,意味着当到 Map 的接口被修改时,有许多地方都要跟着改。你或许会认为这样的改动不太可能发生,不过,当 Java 5 加入对泛型的支持时,的确发生了改动。我们也的确见到一些系统因为要做大量改动才能自由使用 Map 类,而无法使用泛型。
A cleaner way to use Map might look like the following. No user of Sensors would care one bit if generics were used or not. That choice has become (and always should be) an implementation detail.
使用 Map 的更整洁的方式大致如下。Sensors 的用户不必关心是否用了泛型,那将是(也该是)实现细节才关心的。
java
public class Sensors {
private Map sensors = new HashMap();
public Sensor getById(String id) {
return (Sensor) sensors.get(id);
}
//snip
}The interface at the boundary (Map) is hidden. It is able to evolve with very little impact on the rest of the application. The use of generics is no longer a big issue because the casting and type management is handled inside the Sensors class.
边界上的接口(Map)是隐藏的。它能随来自应用程序其他部分的极小的影响而变动。对泛型的使用不再是个大问题,因为转换和类型管理是在 Sensors 类内部处理的。
This interface is also tailored and constrained to meet the needs of the application. It results in code that is easier to understand and harder to misuse. The Sensors class can enforce design and business rules.
该接口也经过仔细修整和归置以适应应用程序的需要。结果就是得到易于理解、难以被误用的代码。Sensors 类推动了设计和业务的规则。我们并不建议总是以这种方式封装 Map 的使用。
We are not suggesting that every use of Map be encapsulated in this form. Rather, we are advising you not to pass Maps (or any other interface at a boundary) around your system. If you use a boundary interface like Map, keep it inside the class, or close family of classes, where it is used. Avoid returning it from, or accepting it as an argument to, public APIs.
我们建议不要将 Map(或在边界上的其他接口)在系统中传递。如果你使用类似 Map 这样的边界接口,就把它保留在类或近亲类中。避免从公共 API 中返回边界接口,或将边界接口作为参数传递给公共 API。
8.2 EXPLORING AND LEARNING BOUNDARIES 浏览和学习边界
Third-party code helps us get more functionality delivered in less time. Where do we start when we want to utilize some third-party package? It’s not our job to test the third-party code, but it may be in our best interest to write tests for the third-party code we use.
第三方代码帮助我们在更少时间内发布更丰富的功能。在利用第三方程序包时,该从何处入手呢?我们没有测试第三方代码的职责,但为要使用的第三方代码编写测试,可能最符合我们的利益。
Suppose it is not clear how to use our third-party library. We might spend a day or two (or more) reading the documentation and deciding how we are going to use it. Then we might write our code to use the third-party code and see whether it does what we think. We would not be surprised to find ourselves bogged down in long debugging sessions trying to figure out whether the bugs we are experiencing are in our code or theirs.
设想第三方代码库的使用方法并不清楚。我们可能会花上一两天(或者更多)时间阅读文档,决定如何使用。然后,我们会编写使用第三方代码的代码,看看是否如我们所愿地工作。陷入长时间的调试、找出在我们或他们代码中的缺陷,这可不是什么稀罕事。
Learning the third-party code is hard. Integrating the third-party code is hard too. Doing both at the same time is doubly hard. What if we took a different approach? Instead of experimenting and trying out the new stuff in our production code, we could write some tests to explore our understanding of the third-party code. Jim Newkirk calls such tests learning tests.1
学习第三方代码很难。整合第三方代码也很难。同时做这两件事难上加难。如果我们采用不同的做法呢?不要在生产代码中试验新东西,而是编写测试来遍览和理解第三方代码。Jim Newkirk 把这叫做学习性测试(learning tests)1。
- [BeckTDD], pp. 136–137.
In learning tests we call the third-party API, as we expect to use it in our application. We’re essentially doing controlled experiments that check our understanding of that API. The tests focus on what we want out of the API.
在学习性测试中,我们如在应用中那样调用第三方代码。我们基本上是在通过核对试验来检测自己对那个 API 的理解程度。测试聚焦于我们想从 API 得到的东西。
8.3 LEARNING LOG4J 学习 log4j
Let’s say we want to use the apache log4j package rather than our own custom-built logger. We download it and open the introductory documentation page. Without too much reading we write our first test case, expecting it to write “hello” to the console.
比如,我们想使用 apache log4j 包来代替自定义的日志代码。我们下载了 log4j,打开介绍文档页。无需看太久,就编写了第一个测试用例,希望它能向控制台输出 hello 字样。
java
@Test
public void testLogCreate() {
Logger logger = Logger.getLogger(“MyLogger”);
logger.info(“hello”);
}When we run it, the logger produces an error that tells us we need something called an Appender. After a little more reading we find that there is a ConsoleAppender. So we create a ConsoleAppender and see whether we have unlocked the secrets of logging to the console.
运行,logger 发生了一个错误,告诉我们需要用 Appender。再多读一点文档,我们发现有个 ConsoleAppender。于是我们创建了一个 ConsoleAppender,再看是否能解开向控制台输出日志的秘诀。
java
@Test
public void testLogAddAppender() {
Logger logger = Logger.getLogger(“MyLogger”);
ConsoleAppender appender = new ConsoleAppender();
logger.addAppender(appender);
logger.info(“hello”);
}This time we find that the Appender has no output stream. Odd—it seems logical that it’d have one. After a little help from Google, we try the following:
比如,我们想使用 apache log4j 包来代替自定义的日志代码。我们下载了 log4j,打开介绍文档页。无需看太久,就编写了第一个测试用例,希望它能向控制台输出 hello 字样。
java
@Test
public void testLogAddAppender() {
Logger logger = Logger.getLogger(“MyLogger”);
logger.removeAllAppenders();
logger.addAppender(new ConsoleAppender(
new PatternLayout(“%p %t %m%n”),
ConsoleAppender.SYSTEM_OUT));
logger.info(“hello”);
}That worked; a log message that includes “hello” came out on the console! It seems odd that we have to tell the ConsoleAppender that it writes to the console.
这回行了;hello 字样的日志信息出现在控制台上!必须告知 ConsoleAppender,让它往控制台写字,看起来有点奇怪。
Interestingly enough, when we remove the ConsoleAppender.SystemOut argument, we see that “hello” is still printed. But when we take out the PatternLayout, it once again complains about the lack of an output stream. This is very strange behavior.
很有趣,当我们移除 ConsoleAppender.SystemOut 参数时,那个 hello 字样仍然输出到屏幕上。但如果取走 PatternLayout,就会出现关于没有输出流的错误信息。这实在太古怪了。
Looking a little more carefully at the documentation, we see that the default ConsoleAppender constructor is “unconfigured,” which does not seem too obvious or useful. This feels like a bug, or at least an inconsistency, in log4j.
再仔细看看文档,我们看到默认的 ConsoleAppender 构造器是“未配置”的,这看起来并不明显或没什么用,反而像是 log4j 的一个缺陷,或者至少是前后不太一致。
A bit more googling, reading, and testing, and we eventually wind up with Listing 8-1. We’ve discovered a great deal about the way that log4j works, and we’ve encoded that knowledge into a set of simple unit tests.
再搜索、阅读、测试,最终我们得到代码清单 8-1。我们极大地发掘了 log4j 的工作方式,也将得到的知识融入了一系列简单的单元测试中。
Listing 8-1 LogTest.java
代码清单 8-1 LogTest.java
java
public class LogTest {
private Logger logger;
@Before
public void initialize() {
logger = Logger.getLogger(“logger”);
logger.removeAllAppenders();
Logger.getRootLogger().removeAllAppenders();
}
@Test
public void basicLogger() {
BasicConfigurator.configure();
logger.info(“basicLogger”);
}
@Test
public void addAppenderWithStream() {
logger.addAppender(new ConsoleAppender(
new PatternLayout(“%p %t %m%n”),
ConsoleAppender.SYSTEM_OUT));
logger.info(“addAppenderWithStream”);
}
@Test
public void addAppenderWithoutStream() {
logger.addAppender(new ConsoleAppender(
new PatternLayout(“%p %t %m%n”)));
logger.info(“addAppenderWithoutStream”);
}
}Now we know how to get a simple console logger initialized, and we can encapsulate that knowledge into our own logger class so that the rest of our application is isolated from the log4j boundary interface.
现在我们知道如何初始化一个简单的控制台日志器,也能把这些知识封装到自己的日志类中,好将应用程序的其他部分与 log4j 的边界接口隔离开来。
8.4 LEARNING TESTS ARE BETTER THAN FREE 学习性测试的好处不只是免费
The learning tests end up costing nothing. We had to learn the API anyway, and writing those tests was an easy and isolated way to get that knowledge. The learning tests were precise experiments that helped increase our understanding.
学习性测试毫无成本。无论如何我们都得学习要使用的 API,而编写测试则是获得这些知识的容易而不会影响其他工作的途径。学习性测试是一种精确试验,帮助我们增进对 API 的理解。
Not only are learning tests free, they have a positive return on investment. When there are new releases of the third-party package, we run the learning tests to see whether there are behavioral differences.
学习性测试不光免费,还在投资上有正面的回报。当第三方程序包发布了新版本,我们可以运行学习性测试,看看程序包的行为有没有改变。
Learning tests verify that the third-party packages we are using work the way we expect them to. Once integrated, there are no guarantees that the third-party code will stay compatible with our needs. The original authors will have pressures to change their code to meet new needs of their own. They will fix bugs and add new capabilities. With each release comes new risk. If the third-party package changes in some way incompatible with our tests, we will find out right away.
学习性测试确保第三方程序包按照我们想要的方式工作。一旦整合进来,就不能保证第三方代码总与我们的需要兼容。原作者不得不修改代码来满足他们自己的新需要。他们会修正缺陷、添加新功能。风险伴随新版本而来。如果第三方程序包的修改与测试不兼容,我们也能马上发现。
Whether you need the learning provided by the learning tests or not, a clean boundary should be supported by a set of outbound tests that exercise the interface the same way the production code does. Without these boundary tests to ease the migration, we might be tempted to stay with the old version longer than we should.
无论你是否需要通过学习性测试来学习,总要有一系列与生产代码中调用方式一致的输出测试来支持整洁的边界。不使用这些边界测试来减轻迁移的劳力,我们可能会超出应有时限,长久地绑在旧版本上面。
8.5 USING CODE THAT DOES NOT YET EXIST 使用尚不存在的代码
There is another kind of boundary, one that separates the known from the unknown. There are often places in the code where our knowledge seems to drop off the edge. Sometimes what is on the other side of the boundary is unknowable (at least right now). Sometimes we choose to look no farther than the boundary.
还有另一种边界,那种将已知和未知分隔开的边界。在代码中总有许多地方是我们的知识未及之处。有时,边界那边就是未知的(至少目前未知)。有时,我们并不往边界那边看过去。
A number of years back I was part of a team developing software for a radio communications system. There was a subsystem, the “Transmitter,” that we knew little about, and the people responsible for the subsystem had not gotten to the point of defining their interface. We did not want to be blocked, so we started our work far away from the unknown part of the code.
好多年以前,我曾在一个开发无线通信系统软件的团队中工作。该系统有个子系统 Transmitter(发送机)。我们对 Transmitter 知之甚少,而该子系统的开发者还没有对接口进行定义。我们不想受这种事阻碍,就从距未知那部分代码很远处开始工作。
We had a pretty good idea of where our world ended and the new world began. As we worked, we sometimes bumped up against this boundary. Though mists and clouds of ignorance obscured our view beyond the boundary, our work made us aware of what we wanted the boundary interface to be. We wanted to tell the transmitter something like this:
对于我们的世界如何结束、新世界如何开始,我们有许多好主意。工作时,我们偶尔会跨越那道边界。尽管云雾遮挡了我们看向边界那边的视线,我们还是从工作中了解到我们想要的边界接口是什么样的。我们想要告知发送机一些事:
Key the transmitter on the provided frequency and emit an analog representation of the data coming from this stream.
对于我们的世界如何结束、新世界如何开始,我们有许多好主意。工作时,我们偶尔会跨越那道边界。
We had no idea how that would be done because the API had not been designed yet. So we decided to work out the details later.
尽管云雾遮挡了我们看向边界那边的视线,我们还是从工作中了解到我们想要的边界接口是什么样的。我们想要告知发送机一些事:
To keep from being blocked, we defined our own interface. We called it something catchy, like Transmitter. We gave it a method called transmit that took a frequency and a data stream. This was the interface we wished we had.
为了不受阻碍,我们定义了自己使用的接口。我们给它取了个好记的名字,比如 Transmitter。我们给它写了个名为 transmit 的方法,获取频率参数和数据流。这就是我们希望得到的接口。
One good thing about writing the interface we wish we had is that it’s under our control. This helps keep client code more readable and focused on what it is trying to accomplish.
编写我们想得到的接口,好处之一是它在我们控制之下。这有助于保持客户代码更可读,且集中于它该完成的工作。
In Figure 8-2, you can see that we insulated the CommunicationsController classes from the transmitter API (which was out of our control and undefined). By using our own application specific interface, we kept our CommunicationsController code clean and expressive. Once the transmitter API was defined, we wrote the TransmitterAdapter to bridge the gap. The ADAPTER2 encapsulated the interaction with the API and provides a single place to change when the API evolves.
在图 8-2 中可以看到,我们将 CommunicationsController 类从发送器 API(该 API 不受我们控制,而且还没定义)中隔离出来。通过使用符合应用程序的接口,CommunicationsController 代码整洁且足以表达其意图。一旦发送器 API 被定义出来,我们就编写 TransmitterAdapter 来跨接。ADAPTER[1]封装了与 API 的互动,也提供了一个当 API 发生变动时唯一需要改动的地方。
- See the Adapter pattern in [GOF].
Figure 8-2 Predicting the transmitter
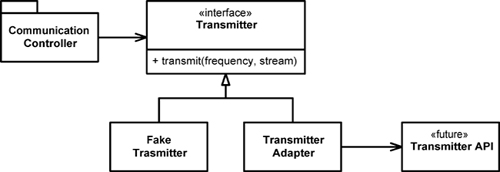
This design also gives us a very convenient seam3 in the code for testing. Using a suitable FakeTransmitter, we can test the CommunicationsController classes. We can also create boundary tests once we have the TransmitterAPI that make sure we are using the API correctly.
这套设计方案为测试提供了一种极为方便的接缝[2]。使用适当的 FakeTransmitter,我们就能测试 CommunicationsController 类。在拿到 TransmitterAPI 时,我们也能创建确保正确使用 API 的边界测试。
- See more about seams in [WELC].
8.6 CLEAN BOUNDARIES 整洁的边界
Interesting things happen at boundaries. Change is one of those things. Good software designs accommodate change without huge investments and rework. When we use code that is out of our control, special care must be taken to protect our investment and make sure future change is not too costly.
边界上会发生有趣的事。改动是其中之一。有良好的软件设计,无需巨大投入和重写即可进行修改。在使用我们控制不了的代码时,必须加倍小心保护投资,确保未来的修改不至于代价太大。
Code at the boundaries needs clear separation and tests that define expectations. We should avoid letting too much of our code know about the third-party particulars. It’s better to depend on something you control than on something you don’t control, lest it end up controlling you.
边界上的代码需要清晰的分割和定义了期望的测试。应该避免我们的代码过多地了解第三方代码中的特定信息。依靠你能控制的东西,好过依靠你控制不了的东西,免得日后受它控制。
We manage third-party boundaries by having very few places in the code that refer to them. We may wrap them as we did with Map, or we may use an ADAPTER to convert from our perfect interface to the provided interface. Either way our code speaks to us better, promotes internally consistent usage across the boundary, and has fewer maintenance points when the third-party code changes.
我们通过代码中少数几处引用第三方边界接口的位置来管理第三方边界。可以像我们对待 Map 那样包装它们,也可以使用 ADAPTER 模式将我们的接口转换为第三方提供的接口。采用这两种方式,代码都能更好地与我们沟通,在边界两边推动内部一致的用法,当第三方代码有改动时修改点也会更少。